
dbt Semantic Layer vs Looker LookML

Last month, dbt announced the general availability of their Semantic Layer and Looker announced a preview of their semantic layer Open SQL interface.
This is a good opportunity to compare the new universal semantic layer with the old “semantic layer of the modern data stack”: LookML.
A semantic what?
A semantic layer is a single place to define common business concepts of data (such as what is a customer or how to count revenue).
Shared definitions can be re-used by different users in an organization, like a monthly KPI report, a data exploration done in Tableau, or a data science analysis. If you have a semantic layer, more data users get safer, easier, and more consistent access to data, as many have said over the last few years (yours truly included).
This comparison covers different aspects:
- The developer view: how easy is it to build
- The analytics team view: how flexible it is
- The engineer view: performance and maintenance
- The CFO view: cost
The basics: who are they
dbt semantic layer is a standalone layer shared by different tools. It comes from dbt’s acquisition of Transform in early 2023. (dbt previously built something on their own and scraped the effort)
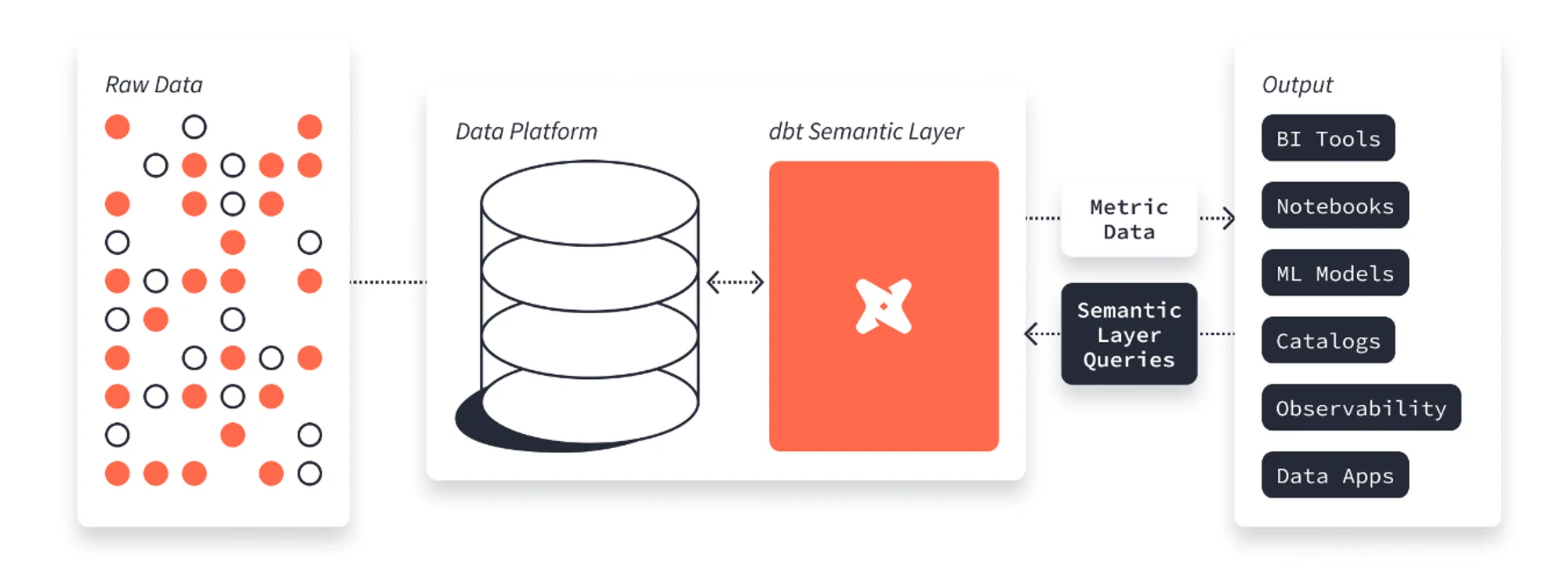
Looker (acquired by Google in 2020) started as a BI tool bundled with a semantic layer called LookML.
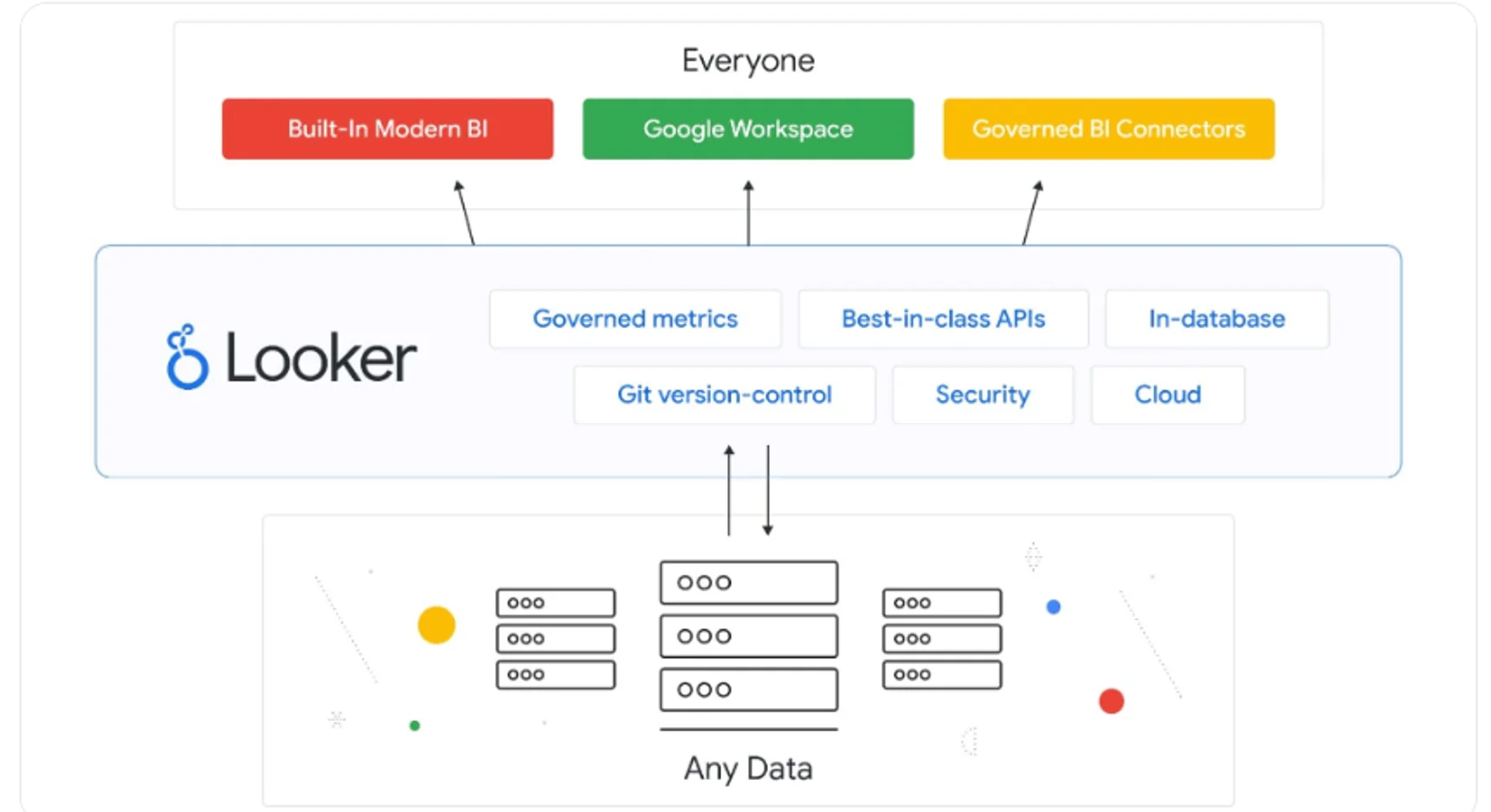
However, recently Google moved LookML towards being a universal semantic layer: it has native integrations with Google Sheets, Tableau and PowerBI. The Looker Modeler provides integration with 3rd parties like ThoughtSpot.
Today, both dbt and LookML are a universal semantic layer: Users can use a BI tool like Tableau or a a data science notebook like Jupyter. Every tool will use the same semantics.
Integrations
dbt semantic layer supports GraphQL (an API), JDBC, as well as BI tools: Tableau (beta), Google Sheets, and a few smaller BI players such as Hex.
Looker supports REST (an API), JDBC, as well as BI tools: Looker (itself), PowerBI, Tableau (beta), Google Sheets. Support for non-Looker tools is limited today to data on BigQuery only.
In addition, Looker can deliver semantics as a table in the database (not limited to BigQuery).
If your data is in BigQuery, Looker has more integrations. Otherwise, dbt would probably be a better choice.
Note – the JDBC interface to common tools such as Tableau is in beta or public preview in both dbt and Looker. So to be fair, might be better to wait to use either tool with JDBC in production use cases.
Development Experience
Productivity is a key metric when evaluating a semantic layer.
Who can maintain it? How easy is it?
Changes to semantics happen all the time, so it matters a lot whether they take an hour or a day.
Both Looker and dbt rely on text files in their own propriety format to define the semantic layer itself. They both can store those text files in a git repository, enabling versioning and code review.
Both of them include a cloud IDE to edit those files and to deploy results.
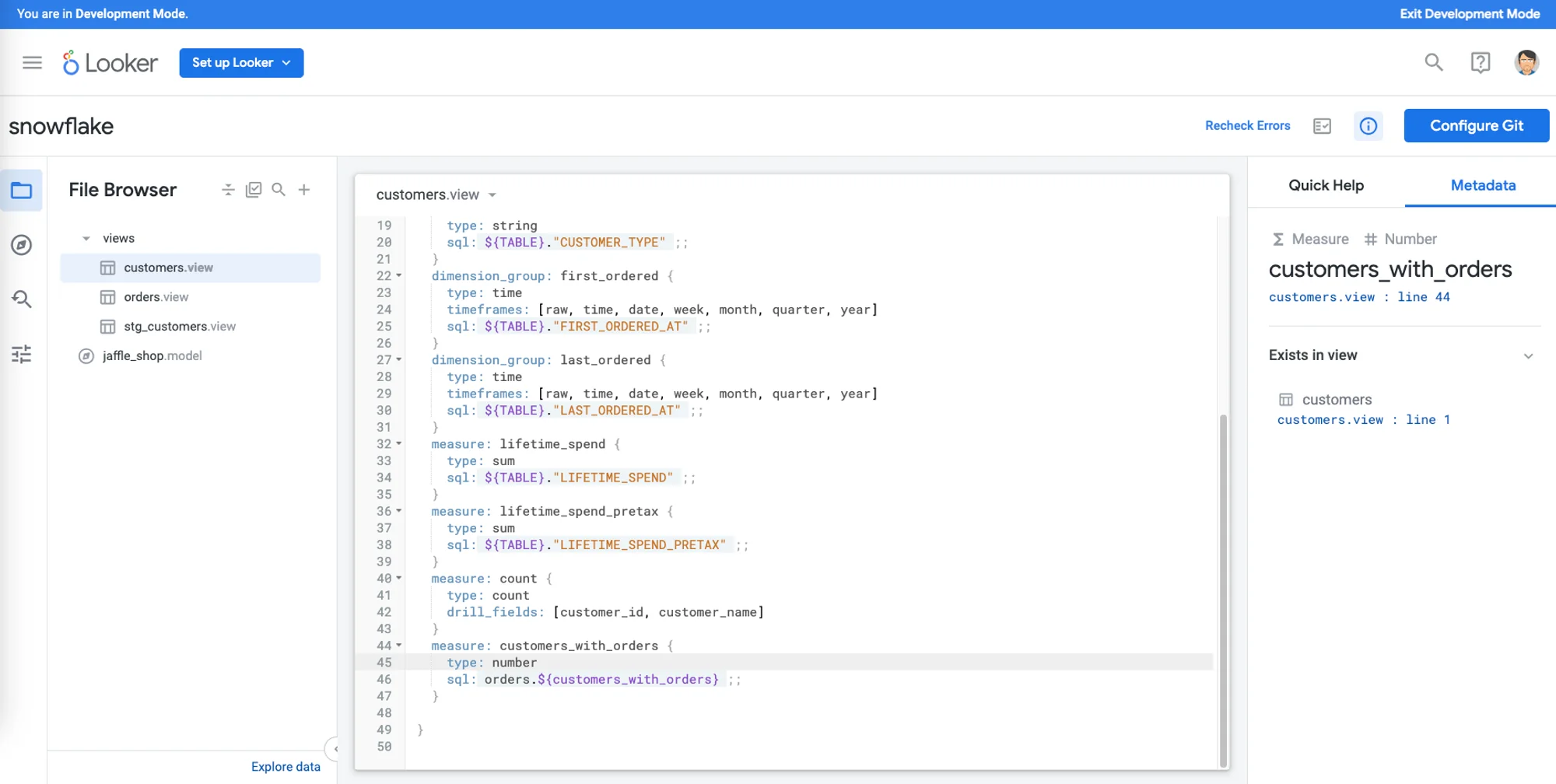
The LookML developer experience is based on tight integration between the IDE (LookML) and a BI tool to explore its output. Changes in LookML reflect immediately in the BI, and logic built in BI can be easily exported into code. The IDE has auto-complete and contextual hints.
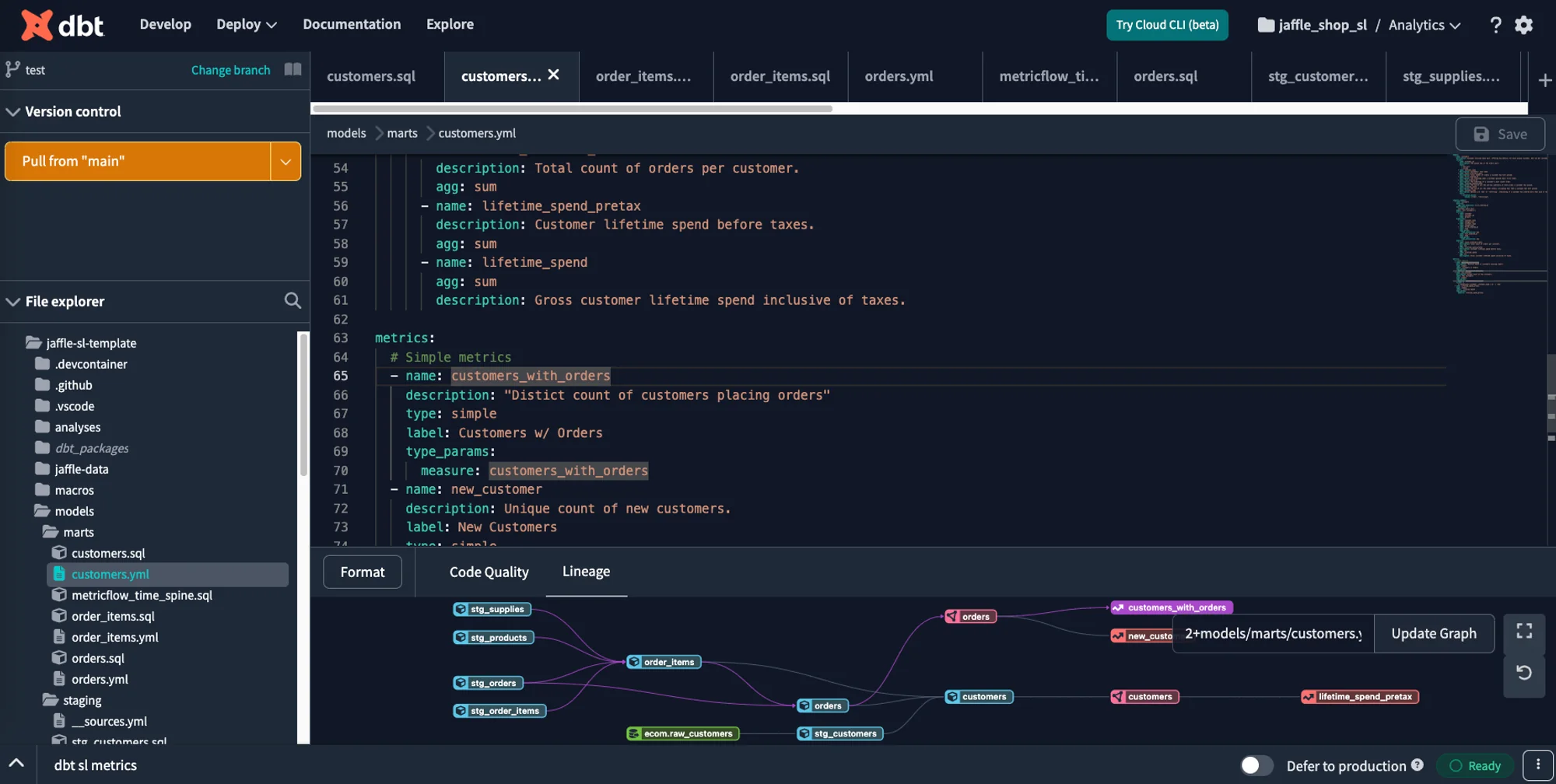
The dbt developer cloud experience is geared much more toward a developer mindset. The main API to test data is GraphQL queries that come from a command line tool or a web tool that speaks GraphQL. The development flow is based on a build-compile-deploy run with an IDE. The IDE has lineage and tabs. Changes to the semantic layer in the cloud IDE do not immediately reflect in tools connected to the semantic layer [^ note: this seems like a bug, not a feature].
The dbt semantic layer YAML has a steeper learning curve than LookML due to less instrumentation in the IDE – and due to having more complex concepts like entities or metrics. Most analysts will find the GraphQL API or the CLI tool very different from their experience of using BI or the experience of using SQL.
The winner is Looker – having the ability to quickly “close the loop” and test a piece of logic with BI is a significant time saver. Furthermore, building directly in BI makes the semantic layer more accessible and easier to learn.
Expressiveness
Expressiveness is roughly defined as “what can you easily say” with it.
The world of data in an enterprise is built of thousands of pieces of information – metrics, dimensions, entities, relationships. What is a user, or how is revenue counted?
One of the largest costs part of implementing a semantic layer is the cost of the team that maintains those pieces of information. An expressive semantic layer requires less work to maintain and less expertise to use right. Conversely, a less expressive semantic layer is a world full of pain and ugly hacks.
The differences between dbt MetricFlow and LookML are major: they speak different languages.
Relationships and Entities
Most data does not sit in one table. It requires JOINs and understanding how different tables relate. Tables might represent business entities.
dbt has a global concept of “entity” that Looker lacks, which is a strong advantage and can help model data well.
However, dbt entities have limited usability due to JOIN limitations:
- Multi-hop joins: What if to connect between two tables one needs to go through an intermediate join? This is a very common scenario in most database schemas: consider a 3 table schema of Customers → Orders → Payments. Looker can automatically resolve the join path between customers and payments (via orders). The dbt semantic layer does not support multi-hop joins, requiring pre-joining data before connecting it.
- Fan-out joins: How to count a metric that requires a join with row duplication? This a common scenario with one-to-many relationships (for example when a Customers table is joined with an Orders table, every customer is each order row). Looker supports some Fan-out joins with Symmetric Aggregates. The dbt semantic layer will fail a query that requires a fan-out join.
The clear winner is Looker – real-world data schemas (such as the Salesforce objects schema) are full of multi-hop or fan-out joins. (*as well as relationships neither Looker nor dbt support). Not being able to model those reduces the value of a semantic layer.
Metrics
The key language of data is metrics: how to count users or revenue.
Here is dbt semantic layer strongest advantage – dbt treats metrics as a re-usable component. Many types of metrics are easy in dbt and hard with LookML. Specifically:
- Metrics counted in different times: dbt allows to easily define for metrics which time column it they are counted on. For example, active users can be counted based on the last activity date while installations are counted based on the first activity date.
- Metrics based on time offset: dbt allows to easily define metrics such as “last month’s revenue”, for example to use for month-over-month growth
- Cumulative metrics: dbt allows to easily define metrics such as “total revenue so far”.
Those metrics can be defined in LookML but it can get tedious and complex (see for example the 8 ways to build a month-over-month metric). Some of those Looker can only easily do it in a dashboard (called a “table calculation”), but not as a reusable metric.
The winner is dbt – complex metrics made easy.
Performance
How much time would it take a query using the semantic layer to return?
Both Looker and dbt server generate queries that hit the database underneath. The overhead of the semantic layer is small (about a second in our tests of dbt), which means the performance is mainly based on two factors:
Quality of generated queries – can the database execute the query fast?
This is highly dependent on the quality of the query generator. Query generation is context-specific. Any fair comparison requires implementing the same business domain in both, which is not in the scope of this blog post 🙂. For the relatively simple queries we tried, dbt and Looker seemed on par.
Which optimizations does the semantic layer offer?
dbt semantic layer does not do any data processing of its own – all processing is done by the date warehouse underneath (such as Snowflake). So does Looker, by default.
However, Looker has two important strategies to improve performance:
- Aggregate Awareness: maintaining and automatically using pre-aggregated tables.
- Caching: keeping query results and skipping the database when relevant
The winner is Looker. Aggregate awareness can deliver an order-of-magnitude improvement over querying tables directly. While it is possible to construct aggregated tables with plain dbt, it takes away from the flexibility of the semantic layer.
Cost
Both Looker and dbt lack transparency on the cost aspects.
dbt: The semantic layer pricing model appears to be consumption-based. Prices are unknown.
The package offered today (Nov 2023) is bundled with a dbt cloud account ($100/ seat), and comes with just 1,000 query units per month (equivalent to a single dashboard with 10 metrics, refreshing 3 times a day). The pricing for a query unit has not been announced.
The code under dbt semantic layer is source-available: it is open but not free.
Looker: Looker pricing model for Looker-as-BI is user-based, starting from $5k/ month. The Standard edition includes 12 users, and can scale up to 50 users for $60/standard user. Access with a 3rd party API is limited to just 1000 calls per month ($5 per call!), however, higher tier editions are more geared towards API usage. No public pricing is available.
In both cases, the direct cost of the semantic layer does not include:
- The cost of the data warehouse processing – depends on the quality of generated queries.
- The cost of data transfer – Looker has an advantage when data stays within.
- Enterprise tier features, such as SSO or private VPC.
There are no winners here, but there is an opportunity for dbt.
IMHO, Looker requires a too-steep entry price for SMBs. However, its pricing model has a strong advantage: query as much as you want (*as long as you use Looker to do it).
dbt’s approach (pay-per-query) might make more sense for a decoupled semantic layer. If they can keep it low and predictable for heavy workloads, they can have an advantage.
Bottom Line
If you are on any other data source – dbt semantic layer is well worth a look; but be wary if your schema has many JOINs. It still has a way to go compared to what mature semantic layers such as LookML can do.
If all your data is on BigQuery – Looker LookML wins on most fronts: developer experience, expressiveness, performance, and integrations. It’s almost a no-brainer.
If you are on Snowflake, check out Honeydew.
Honeydew Semantic Layer
Honeydew is a modern semantic layer native to Snowflake. Honeydew enables to decouple between semantics and the user tools that consume them.
There are a few distinct differences between Honeydew and dbt or LookML:
- User Tool Support: Honeydew has a SQL API, enabling the reuse of metrics in any tool. It supports all the major BI tools (SaaS and On-Prem) – such as PowerBI, Tableau, and Looker.
- Complex Semantics: Honeydew supports composable metrics, enabling to create complex logic with ease. Metrics can also be used to build data marts.
- Development Experience: dbt and LookML are code-first. Honeydew’s is multi-modal: Semantics can be edited in code by engineers (similar to dbt), in UI by analysts (similar to tools such as Tableau), and with API.
- Snowflake Native: Honeydew is native to Snowflake in its integrations and way of operation, including how queries are generates and caches are managed.
- No Data Movement: Honeydew operates in your Snowflake environment.
Want to know more? Set up a demo any time.




