Honeydew Managed Pipelines
Honeydew is a repository of shared business logic such as standard metrics and entity definitions.
 Honeydew integrates with dbt to allow an end-to-end analytics pipeline.
Honeydew integrates with dbt to allow an end-to-end analytics pipeline.
Honeydew enables any user tool to consume standard metrics and entities. When a tool like Tableau sends a query, Honeydew transforms it on-the-fly to the right set of JOINs and aggregations based on a shared data model definition.By integrating Honeydew and dbt, you can create a single source of truth from ingestion to Snowflake tables to BI that is based on the same standard definitions.
Pipeline Stages
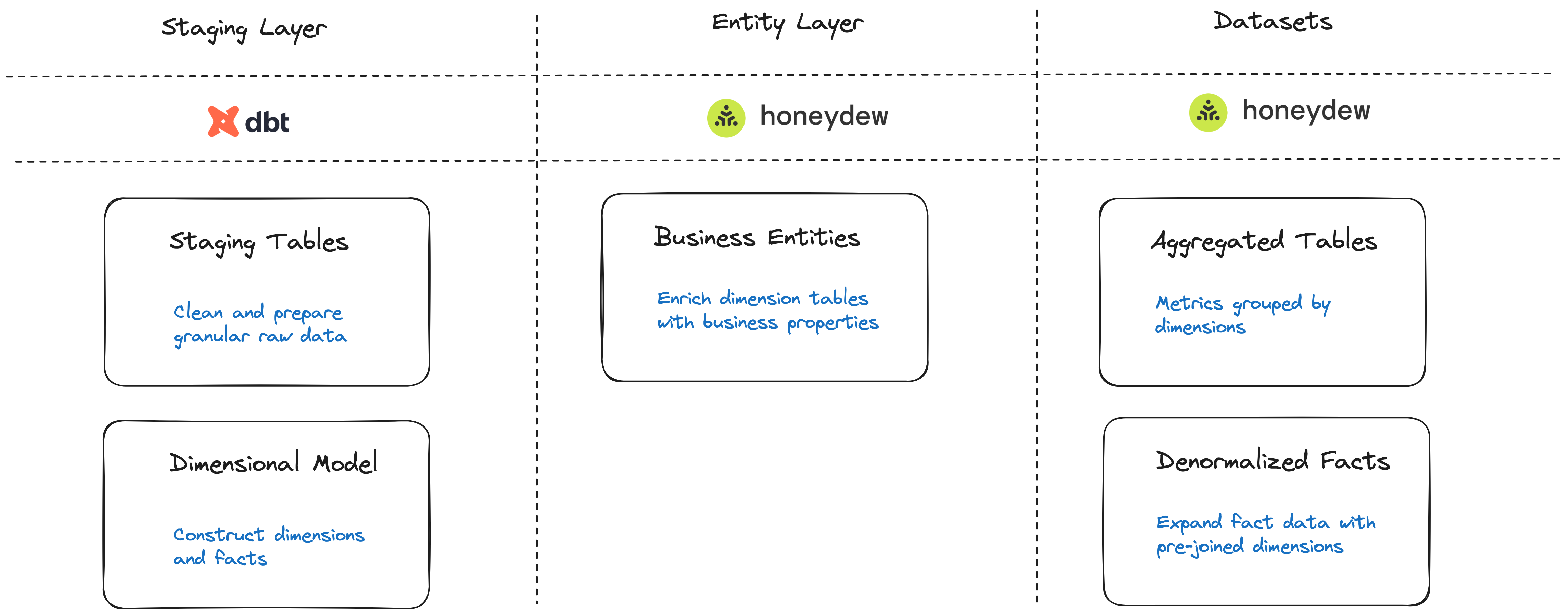
A typical data pipeline of Honeydew with Snowflake and dbt consists of the following stages:
-
Ingestion: Bringing raw data into Snowflake. Usually, with a tool such as Fivetran or similar.
-
Staging: An incremental periodic process that transforms raw data into analytic-ready granular data. The following transformations are typically performed at this stage:
- Data cleanups, normalization, deduplication
- Data merging, change data capture deconstruction
- Dimensional modeling, incremental updates
Implemented using dbt or other transformation tools. Executed by an orchestrator (dbt Cloud, Airflow, etc.) based on a period (i.e. hourly) or change triggers.
-
Entity Layer (Data Mart): A periodic process that transforms granular data into a domain data mart with business entities, metrics and aggregated datasets.
The following transformations are typically performed at this stage:
- Business Entities: Extend granular data with logic properties, such as
- Calculated columns (build an “Age Group” category out of “date of birth”)
- Aggregated properties (first order data, total revenue per customer, etc.)
- Metric Datasets: Build datasets such as:
- Aggregated tables (“Monthly KPIs”)
- Denormalized fact tables
Both are implemented using Honeydew metrics and can be materialized in Snowflake by Honeydew.
For materialization, Honeydew can leverage your dbt pipeline by creating Honeydew-managed dbt models, in the same dbt repository as your staging models.
-
Metric Layer: On-the fly transformation of user queries to JOINs and aggregations over entity tables using standard metrics like “Revenue” or “Active Customer Count”.
Example
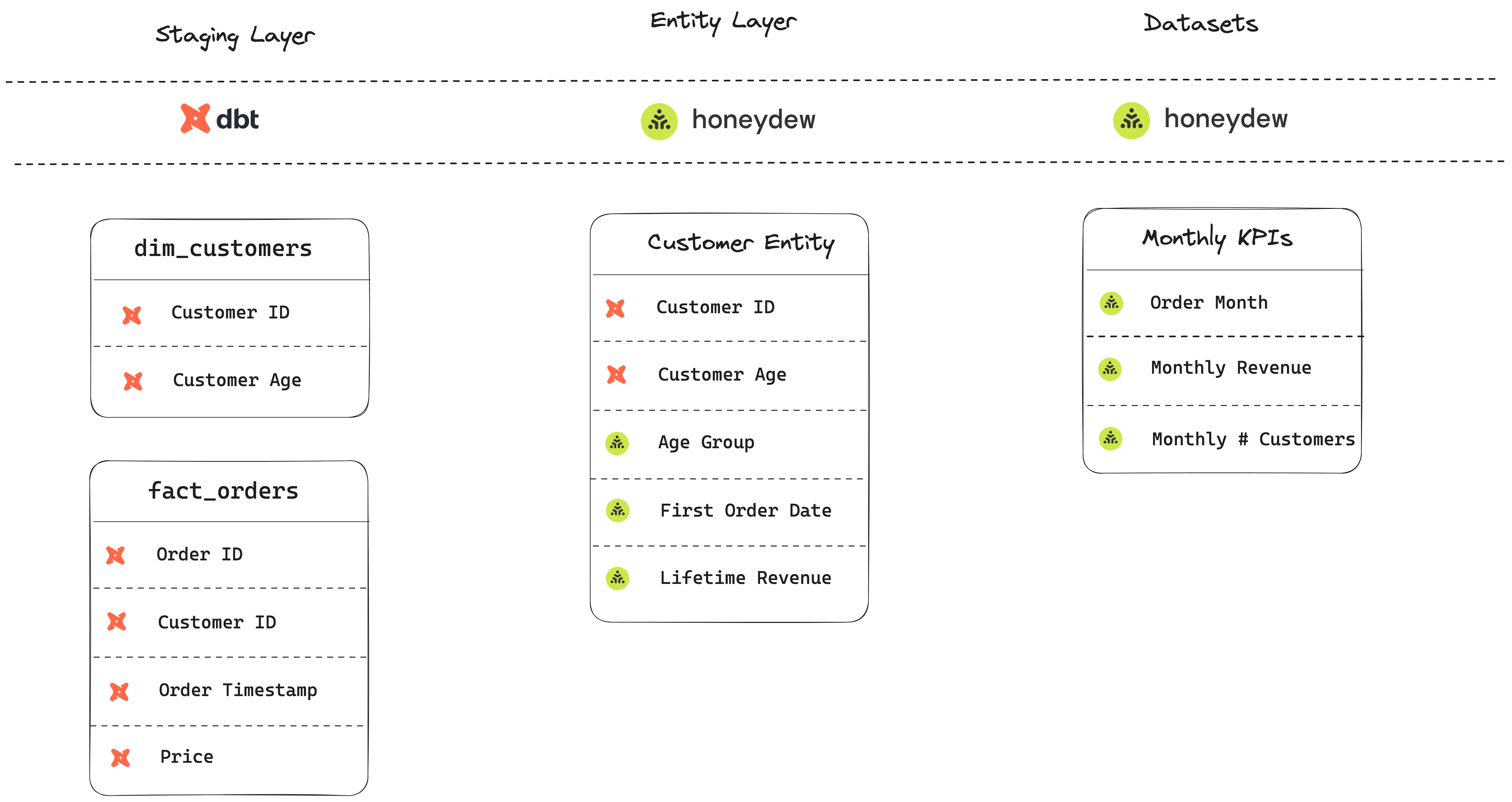
- Ingestion: raw customer tables and raw order events are loaded into Snowflake.
- Staging: dbt models that transform those into two tables:
dim_customers: A customer dimension table, with a row per known customer. Dbt preparation includes clean-up and merging from raw data.fact_orders: An incremental model, with a row per unique order event. Dbt preparation includes handling backfilling and time stamp conversion.
- Data Mart: Honeydew-managed models:
- Entity models, such as
customers: A customer entity table. Includes additional properties:
- “Age Group” - a CASE WHEN that maps ages to categories
- “First Order Data” - an aggregation of order facts that finds first order
- “Lifetime Revenue” - the
revenue standard metric by customer
- Dataset models, such as
monthly_kpis: An aggregated table:
- “Order Month” - based on order timestamp
- “Monthly Revenue” - the
revenue standard metric by order month
- “Monthly # Customers” - a count of customers active in a month