Where you’ll end up
By the end:- A semantic model with
customer,orders,lineitem,part,partsupp,supplier,nation, andregion, plus reusable metrics likerevenue - A domain that exposes a curated slice of the model
- A context layer with one skill and one event
- An agent pairing the domain with that context
- A BI tool (Power BI, Tableau, Excel, etc.) live on the domain
- Deep Analysis answering investigative questions on the same model
What you’ll need
- A Honeydew workspace. Sign up or follow initial setup.
- A connected warehouse with the TPC-H schema available.
- Optional, recommended: a coding agent connected to the Honeydew MCP server with the Honeydew plugin for coding agents. Claude Code, Cursor, VS Code, Gemini, Codex, and other agents all work.
The data
TPC-H is an order-management benchmark that database engines have been competing on for decades. Customers place orders made of line items, parts come from suppliers, customers and suppliers belong to nations, and nations roll up into regions. Orders span six years, starting 1992.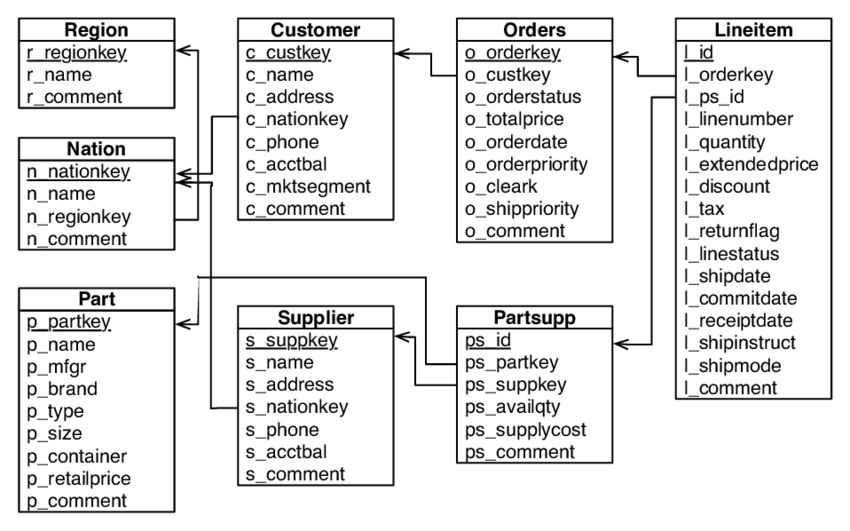
customer, orders,
lineitem, part, partsupp, supplier, nation, and region.
Relations connect them in the same shape as the foreign keys in the
warehouse.
Build the semantic model
1
Entities and relations
A Honeydew entity wraps a table in your
warehouse. The matching Entities on their own don’t get you far. Insights come from connecting
them, and that’s what relations are for: they
tell Honeydew how entities JOIN, in which direction, and on which
columns. The rest follow the same many-to-one shape:
customer wraps the CUSTOMER table, orders wraps
ORDERS, and so on. The entity declares its granularity key (the
column or columns that make a row unique) and points at a source
dataset that maps to the warehouse table.orders is the simplest shape, with a single-column key:type: dataset file binds ORDERS to the actual table:
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS on Snowflake,
samples.tpch.orders on Databricks, or your own loaded copy.Some entities need more than one column as a key. lineitem is one
row per line within an order, so its key is the order key plus the
line number:lineitem is the central fact in this model. Every line item
belongs to one order, so the relation from lineitem to orders is
many-to-one:lineitem to partsupp,
orders to customer, customer and supplier to nation,
nation to region, and partsupp to both part and supplier.
Once the relations are declared, Honeydew handles the JOINs whenever a
query mixes attributes from multiple entities.2
Metrics and attributes
A metric is an aggregation defined once at an
entity’s granularity. Let’s start with Once it’s defined, you can group Metrics also compose. TPC-H Q14 asks what share of revenue came from
promoted parts. That’s a ratio metric on top of the
revenue on lineitem. It’s
the line-item price net of discount, summed across rows:lineitem.revenue by
orders.o_orderdate, customer.c_mktsegment, or nation.n_name, and
Honeydew figures out the JOIN path from the relations you declared in
the previous step.A calculated attribute is like a virtual
column on an entity. TPC-H Q16 marks a supplier as having complaints
when the supplier comment matches a pattern. Let’s codify that as a
reusable attribute on supplier:revenue we
already have:FILTER (WHERE ...) scopes the inner revenue to line items where
the part is a promotion. The JOIN through
lineitem → partsupp → part to reach p_type is figured out by
Honeydew. One expression, three tables.See metrics and
attributes for the reference.
Recipes has more patterns: ratios, year-over-year
growth, active-customer cohorts, and so on.3
A domain
A domain is the part of the model that people and tools
actually query. BI tools query domains. AI agents query domains.
Domains can also apply mandatory filters and parameter overrides, so
the full model stays broad while what a given consumer sees stays
focused:
source_filters apply only when the source entity is in the query;
filters apply to every query on the domain. Domains can inherit from
each other, so shared rules across finance, growth,
supplier_ops, and other domains live in one place. See
domains for both.Run a query
Three ways to query the domain:- Honeydew Studio Playground: pick attributes and metrics interactively; the Playground shows the generated semantic query.
- SQL: through the SQL interface, after connecting a BI tool or any JDBC client.
- Coding agent: through the Honeydew MCP server.
Add an AI layer
1
A context layer
The semantic layer captures what the data means. The
context layer captures
how your organization thinks about it: analytical methods,
historical events, organizational knowledge, AI memory.A skill is a methodology the AI follows when a question matches
its description:An event is something that happened: a launch, a pricing change,
an outage. When a question’s time range overlaps the event, the AI
factors it into the analysis:Instructions, external knowledge from Notion or Confluence, and
AI-generated decision traces round out the five context types. See
context management.
2
An agent
An agent is where the domain and the
context layer meet. It’s what users open in Honeydew Studio, Slack,
Teams, or via MCP to ask a question:The same domain can back more than one agent. A
supplier-ops-analyst
could share the same orders_analytics domain with a different
context set, for example.Ask the AI
Open theorders-analyst agent and ask:
Anything notable about EUROPE and ASIA revenue patterns in late 1997?Deep Analysis plans the investigation, runs a sequence of queries against
orders_analytics,
and uses the skill and event we just built. On the Snowflake TPC-H
sample data, here’s what the agent comes back with:
EUROPE vs ASIA Revenue — Late 1997ASIA led consistently through Q3 with a ~$9–10M gap. October was a near-perfect tie. EUROPE pulled ahead in Q4, reversing the gap. The crossover from ASIA-dominant to EUROPE-dominant in late 1997 is the most notable finding.
Connect a BI tool
Connectorders_analytics to any
supported BI tool. For
programmatic access, use GraphQL or
MCP.
What’s next
Modeling reference
Entities, relations, calculations, domains and advanced
patterns.
Recipes
Cookbook for common metric shapes: ratios, year-over-year
growth, active customers, nested aggregations.
AI Analyst
Deep Analysis, agents and the Context Layer in depth.
BI tool setup
Per-tool guides for Power BI, Tableau, Excel and more.