Introduction to relations
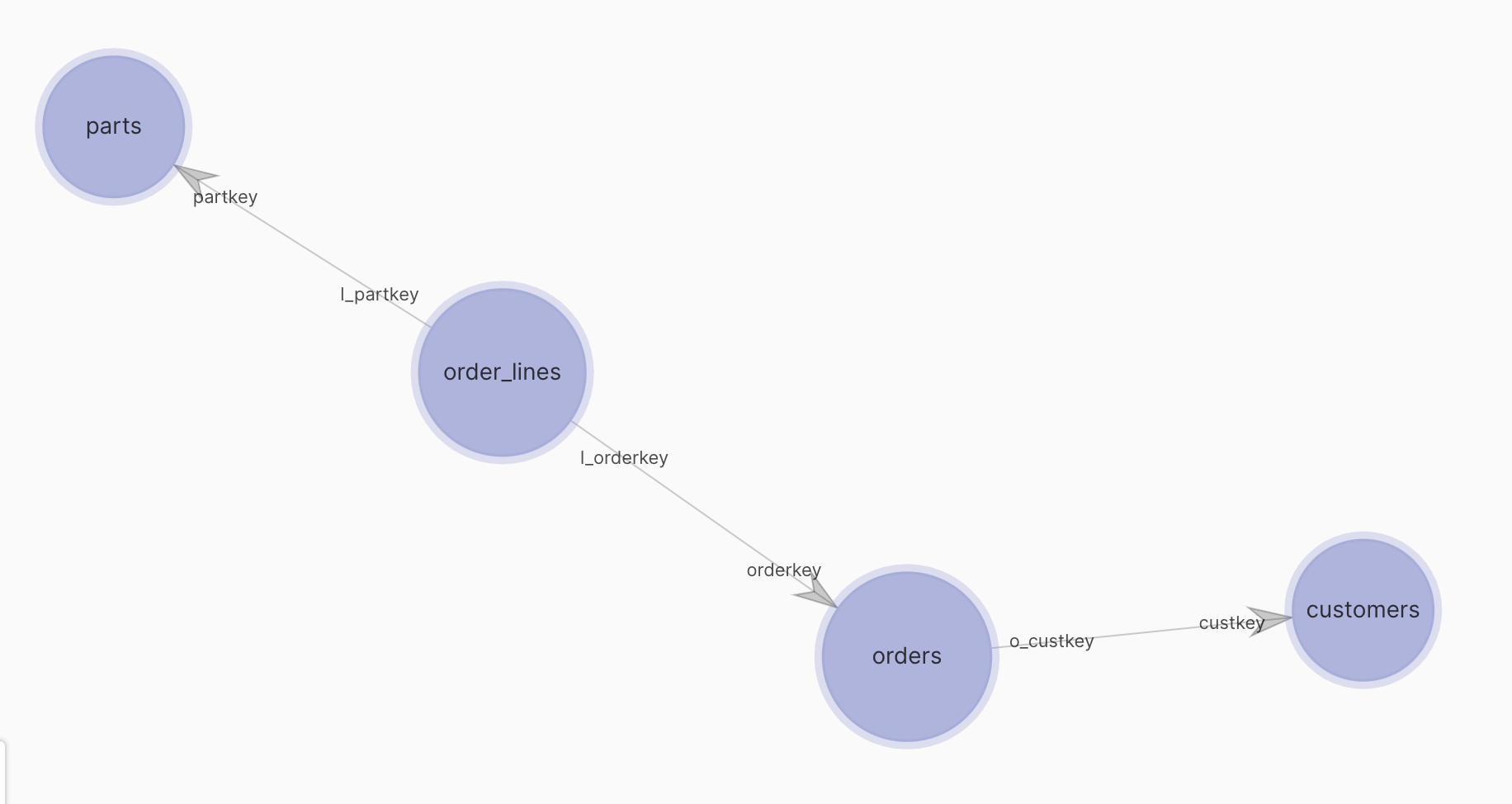
Usually, there is more than one entity in data. For example, TPC-H example has few “natural” entities in the data: customers, orders, line items of an order and parts in a line item. Relations have directions - a customer may have many orders. Each order may have many line items. A Relation in Honeydew connects entities. It can be a 1:1 or a 1:many relationship. The “1” side of a relationship always goes to a Granularity Key of an entity. For example,orders and customers are connected: custkey of orders to custkey of customers. custkey is the granularity key of customers.
- How JOINs are performed between entities
- How filters on entities affect other entities
- How aggregations are performed across entities
Honeydew engine assumes that data fits the relations configuration:
- 1:1 relations are unique on both sides
- 1:many relations are unique on one side
Join Properties
Join Type
Following types are supported:- Inner
- Left
- Right
- Full Outer
Direction
Relationships typically convert to JOINs when are used to compute semantics. The direction (1:many) affects how calculations are performed after the join, by telling the engine which rows are duplicated. See mixing granularities for more information on how that is handled.Honeydew does not support 1:1 relationships. When connecting entities with 1:1 relation choose
a many:1 direction between them, and connect any other shared dimensions between both to the many side.If a 1:1 semantics are a must then create a joint entity (can be done
using custom SQL) and map that instead.
Connection
Connection defines how entities connect. There are two ways to define:- Selecting connecting fields: default mode, for the majority of joins
- Build a SQL expression: for complex joins
Connecting entities using attributes
Relationship must include the choice for source and destination columns. Can define more than one for a composite join connection. Joins based on that definition are always equality joins using the chosen columns.Honeydew validates that the columns match the join direction - i.e. the 1 side of a relationship must be a key.
Example: Fact and Dimension Tables
Given two tables:fact_sales: a fact table tracking order transactions that has a foreign keycustomer_iddim_customer: a dimension table holding current customer information that has a primary keycustomer_id
- Connect on the
customer_idfield from both sides. - Set a “many-to-one” relationship from
fact_salestodim_customer
Sample data:
fact_sales (Fact Table)
dim_customer (Dimension Table)
Result of a query on both:
Connecting entities using a custom SQL expression
Relationships may be set using custom SQL expressions, using any logic to implement the join. It can be set to define an equality join that is equivalent to using connection with fields:-
Filtered joins:
Connect
ƒact_orderswithdim_customerusing a condition -
Range joins:
Connect
ƒact_orderswithdim_customerover a specific time range -
Alternative keys:
Connect
ƒact_orderswithdim_customerusing a field which is not a key ofdim_customer -
Multi-entity joins:
Given that
fact_ordersis connected withdim_regiondimension Connectƒact_orderswithdim_customerusing a field fromdim_region
When using multi-entity joins, each entity in the expression should connect either to the source or the target, but not to both.Using shared (conformed) dimensions for connection expressions is not currently supported.
Example: Fact and a Slowly Changing Dimension (SCD2)
Given two tables:fact_sales: a fact table tracking order transactions that has a foreign keycustomer_iddim_customer: a dimension table tracking customer information over time (SCD Type 2). It has multiple entries percustomer_idwith validity ranges.
valid_from and valid_to:
fact_sales to dim_customer
Sample data:
fact_sales (Fact Table)
dim_customer (SCD2 Dimension Table)
The key for
dim_customer is not customer_id (which is repeating across ranges), but rather a surrogate key (customer_sk)
valid_from / valid_to define the row’s effective period.Also note that valid_to here is an infinity date (9999-12-31). In some settings it is used as NULL instead, in which case can
adjust the join condition accordingly.Union
Honeydew does not support directly a UNION connection between entities. If need to connect tables A and B, create a custom SQL query source data with the following sql:Cross-Filtering
What happens when you query attributes from one entity (customers.name), while filtering on another
entity (parts.brand = 'Brand#55') ? Would you get the list of customers that had orders of parts of that brand,
or would you get all customers?
The answer is based on whether a filter from parts “flows” the path of parts → order_lines → orders → customers
or not. Each relationship can control in what directions can filters pass through (“cross-filter”).
Following settings are supported (given a 1:many relationship):
- Both directions (default)
- From one to many
- From many to one
- Not at all
Filters from many to one have a higher performance impact, as they can require more JOINs to execute.
Default Cross Filtering
Cross filtering options depend on join type:Example Use Cases
Any supported combination can be used. Common use cases include:-
Users look at data from dimensions and facts using filters on both: use
bothcross-filtering andLEFTjoin type. In that case every filter used by the user will propagate to any entity regardless on where it comes from. -
Same, but with referential integrity assumption (i.e. it is never desired to count orders of a non existing
customer):
use
bothcross-filtering andINNERjoin type. In that case every filter used by the user will propagate to any entity regardless on where it comes from. Additionally, any values that do not exist in a dimension will be removed from the fact when joined. -
Users look at metrics based on a fact table, and use a dimension entity only as filter or a group by:
use
one-to-manycross- filtering andRIGHTjoin direction. In that all the values of that dimension always present in a group by, and can filter the fact. -
Dimension entity that is only as part of a filtered metric (typically with
attribute lookup): use
noneandOUTERso no actions on either fact or dimension impact values directly, and only filter the metric.
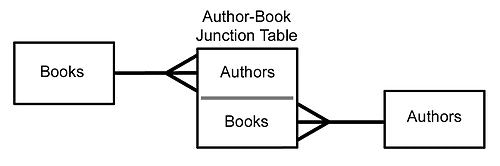
Modeling many:many relations
Honeydew does not support defining a many:many relationship. However a many:many relationship is typically implemented by building a connecting table (sometimes called a “junction” or a “bridge” table). For example authors and books is a many:many relation (authors may write many books, and a book may have multiple authors).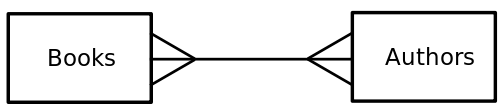
YAML Schema
Relations are defined in the entity YAML. The schema for relation subsection is:target_entity: entity to connect torel_type: logical direction of the relationshipname(optional): identifier for the relation. Auto-generated from entity names if not set (e.g.,orders_to_customers).display_name(optional): human-readable label shown in the UI.description(optional): free-text description of the relation.connection: a list of fields for a join condition. Must fully cover the primary key of the entity on the “one” side of the relation.connection_expr: a custom join expression, ifconnectionis not set. Thesqlexpression may only use attributes.rel_join_type(optional): the type of default join to applycross_filtering(optional): the cross-filtering configuration to apply