Introduction
Many analytic workloads require aggregations or joins on large datasets (such as fact tables), which can be slow or expensive when the data is large. Honeydew can improve the performance of aggregative queries of any kind by leveraging Honeydew-managed pre-aggregations in your data warehouse.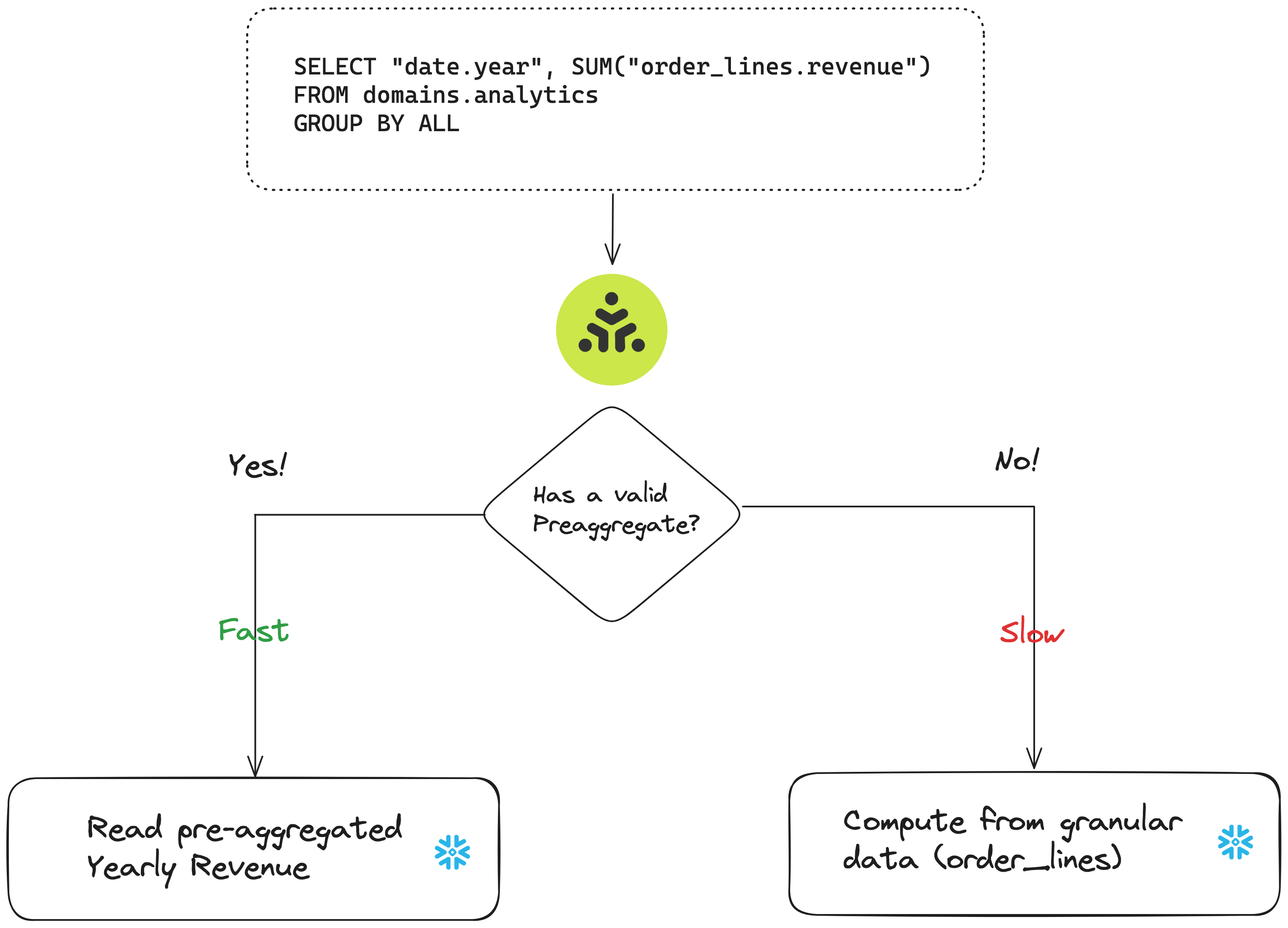
- Metrics that require acceleration (if users commonly ask about daily revenue, can put it in the per-day aggregate).
- Groups that are needed to accelerate user queries (if users commonly ask for metrics by day/month/quarter, can pre-compute per-day results).
- Domain that needs to match user queries (as different domains might have different configurations).
Honeydew checks if the dataset table exists in your data warehouse to use it for acceleration.A dynamic dataset configured for pre-aggregate caching but not yet deployed will not be used.
How It Works
Honeydew automatically matches a user query with a pre-aggregated dataset that can accelerate it. Honeydew verifies all semantic definitions (groups, filters in use, join paths in use) before deciding that a pre-aggregation can serve the user query.Matching Groups
A pre-aggregated dataset will match a user query only when its groups can help the user query.Roll Up Matching
Metric based on additive aggregations (likeSUM) will match the groups in the user query can be computed
by rolling up from the pre-aggregated dataset (see more details below).
For example, if the user count metric is additive (defined as a COUNT), and there is a preaggregate
for total_users by year, city:
- A user query for
total_usersbyyear, citywill match exactly since it has same groups. - A user query for
total_usersbycitywill match and summarize over all years. - A user query for total
total_users(no groups) will match and summarize over all years and cities.
Exact Matching
Metrics based on non-additive aggregations (likeCOUNT(DISTINCT)) will match only when the groups in the
user query are exactly the same as in the pre-aggregated dataset.
For example, if the unique user count metric is non-additive (defined as a COUNT(DISTINCT)), and there is a preaggregate
for unique_users by year, city:
- A user query for
unique_usersbyyear, citywill match exactly since it has same groups. - A user query for
unique_usersbycitywill not match.
Matching Filters
A pre-aggregated dataset will match a user query only when its filters match fully. For example, if the preaggregate dynamic dataset was built for 2023, only queries filtering for 2023 will use it. The user query can be further filtered on groups that match the pre-aggregate. For example, given a preaggregate forrevenue by year and city, where year = 2023:
- A user query for
revenuebyyear, city, whereyear = 2023will use the preaggregate (since it matches all preaggregate filters and groups) - A user query for
revenuebyyear, city, whereyear = 2023 and city='Seattle'will also use the preaggregate (since it matches all preaggregate filters and groups, and its additional filters are on thecitygroup that exists in the pre-aggregated dataset) - A user query for
revenuebyyear, whereyear = 2023 and city='Seattle'will use the preaggregate in the same way, but roll up over all cities to get a yearly total. - A user query for
revenuebyyear, citywithout any filters will not match the preaggregate (since it was not filtered byyear = 2023)
Domains
A pre-aggregated dataset will match a user query only when Source Filters of user’s query domain and the pre-aggregated dataset domain are same.Additive Metrics
Metrics based on aggregation likeCOUNT, SUM, MAX, MIN are additive: they can be “rolled-up” from the preaggregate.
If there is a count metric pre-aggregated for each day, it can be summed up to see value per month.This is called rolling up a metric from groups.
Partial Group Matching
When an aggregate is built over multiple groups with additive metrics, it can serve queries on any group subset. For example, if the revenue metric is additive (defined as aSUM), and there is a preaggregate for
revenue by year, city:
- A user query for
revenuebyyear, citywill match exactly since it has same groups. - A user query for
revenuebycitywill match, and will roll up fromyeargroups to get totals per city. - A user query for
revenuebyyearwill match, and will roll up fromcitygroups to get totals per year. - A user query for total
revenue(no groups) will match, and will roll up from all groups to get the total. - A user query for
revenuebyyear, colorwill not match since it has different groups.
Matching Entity Keys
When an aggregate is built over an entity key group with additive metrics, it can serve queries on any group that comes from an attribute in that entity. For example, if the revenue metric is additive (defined as aSUM), and there is a preaggregate for revenue by
customer.id, then user queries on any group that comes from the customer entity will roll up.
- A user query for
revenuebycustomer.idwill match exactly. - A user query for
revenuebycustomer.namewill match, and will roll up fromcustomer.idlines. - A user query for
revenuebycustomer.name, customer.agewill also match, and roll up. - A user query for
revenuetotals (no groups) will match, and will roll up over all groups to get the total.
Configuring Additive Metrics
Honeydew detects simple additive metrics automatically (metrics that are an aggregation or direct derivatives thereof). Any metric can be set to be additive using therollup metric property:
sum: Run a SUM aggregation to roll up. Used for metrics that are aSUMorCOUNTaggregation.min,max: Run a MIN or MAX aggregation to roll up. Used for the corresponding aggregations.hll: (coming soon) Run an approximate distinct count combine to roll up.no_rollup: Disable roll-up behavior.
Tips for Effective Pre-aggregations
- Build for additive metrics - a single pre-aggregated dataset can serve many queries with roll-ups.
- Don’t use explicit filters on the data - any filter limits user queries that can be served.
- For pre-aggregate caches for workloads that operate on a subset of the data, build them in a filtered domain.
- Use entity keys as groups with additive metrics - more queries can be served with roll-ups from entity keys.
Automatic Aggregate Caching in Snowflake
Honeydew can automatically set up and use aggregate caching in Snowflake based on recent queries. This is most useful for accelerating live queries that calculate a dataset and then slice and dice it, such as Pivot Tables. To enable short term aggregate cache in a domain, add this to the domain YAML:Short-Term Automatic Aggregate Caching is currently in Beta.
Contact support@honeydew.ai to activate it for your account.
Configuration
Pre-aggregated datasets are set up via building a dynamic dataset that is enabled to be used as cache.Configuration when building from ETL code or Honeydew
Set up the cache delivery settings in the Dynamic Dataset YAML schema. The example below is for Snowflake:Configuration when using dbt as orchestrator
Set up in Dynamic Dataset YAML schema cache delivery settings for dbt:Orchestration
Entity Cache refresh relies on external orchestration (with dbt or otherwise) or manual deployments.
Set up with Honeydew
Use the Honeydew deploy functionality to write the dynamic dataset to a table from the UI. For Snowflake, you can also use the Native Application Deploy API:Set up with ETL tools
For Snowflake, use the Native Application API to get SQL for the cache:Dynamic datasets can be defined within a domain. All domain configuration (such as filters) will be
applied to the dynamic dataset used for cache.
Set up with dbt
To set up dbt as a cache orchestrator:- In dbt, create an entity cache model by using the Honeydew dbt cache macro
- In dbt, use the
configmacro to set up materialization settings such as clustering or dynamic tables - In Honeydew, set the entity’s dbt delivery settings to the chosen dbt model name
monthly_kpi model in dbt: