













AI Can Write SQL. It Still Fails as an Analyst.

The first demo of any AI analyst feels magical. Show me Q4 revenue? AI nails it. Show me user growth? A breathtaking interactive infographic in 5 minutes.
AI is getting better and better in writing SQL. Anyone, anywhere can now just ask about the data.
And if I were heading a data team right now, I’d be terrified.
Two scenarios can play out three months into an “ask data” deployment:
The Chaos
The agent ships with full warehouse access. Everyone’s thrilled – until someone notices the revenue numbers don’t match the board deck. The data team investigates and finds 31 different definitions of “monthly recurring revenue” across chat histories. Some count annual contracts monthly, some exclude services, some include. Nobody remembers what the board deck uses.
Excel sprawl feels like the good days.
The Lockdown
Data teams fight back. The agent now only answers questions about carefully curated datasets. Root cause analysis? No dataset for that. Cross-domain questions? Can’t cross those boundaries.
The flexibility that made AI exciting — ask anything! — is gone. At best, you’ve got a very expensive conversational dashboard browser.
What went wrong?
Both Chaos and Lockdown are the same mistake: treating AI as a replacement for the layer that keeps data trustworthy, rather than a consumer of it.
Tools like Claude Code have made it easy to generate a data model with neat tables and metadata – weeks of work now takes hours. But as enterprises find out, generating the model isn’t the hard part. Operating it is:
How do you let anyone ask any question while keeping the answers correct, governed, and consistent?
Better SQL makes this worse, not better
AI writes better queries today than it did three months ago (don’t mind the publish date, this one is going to be a true statement for a while). Agents and LLMs improve – they understand context better, they understand the nuances of SQL better, they can read more metadata.
Counterintuitively, the better AI gets at writing SQL, the bigger the challenge of correctness becomes. As AI makes it easy for more people to build more queries, it makes it easy to be wrong, often.
The thing about data is that unlike so many other things we deal with in life, it has the special property of being right or being wrong. And being wrong with data carries an outsized risk of bad decisions.
There is an infinite number of ways to calculate something wrong. There is usually only one way to be right. You have to ensure every single question gets it right.
What the old stack got right
In the old world, dashboards were built on top of a data model – Tableau’s data sources, Power BI’s semantic models, Looker’s LookML. That model wasn’t just documentation. It was a compiler and an enforcer of constraints.
You defined “revenue” once. Every dashboard on the same data model used the same definition. Security rules applied automatically. Performance optimizations were built in.
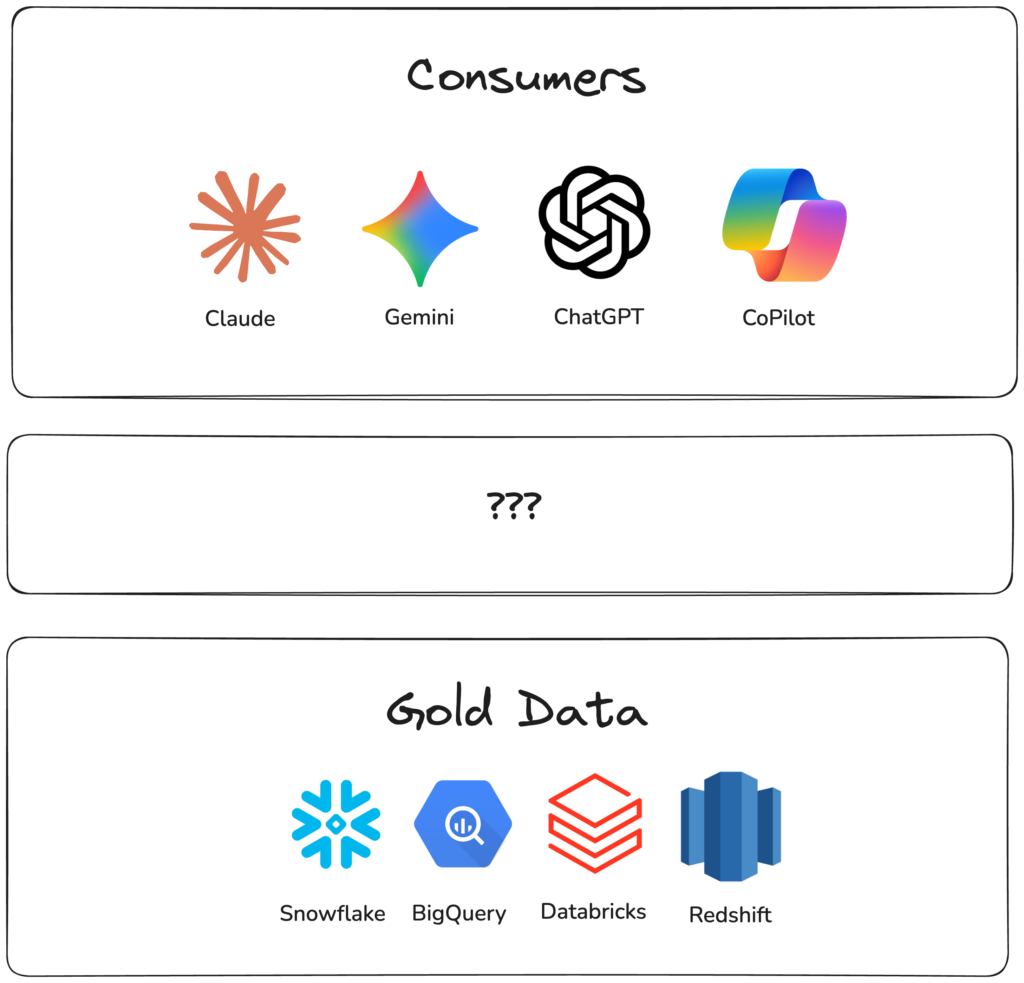
Now, with AI and direct SQL generation, we’re skipping what that layer provided.
There are three key requirements for AI on data at scale:
Guaranteed Correctness
When someone asks “how many active users did we have last weekend?”, calculating that is complicated: engagement sessions, platform differences, time windows, exclusions. You probably have 1500 lines of SQL defining it correctly.
With AI-generated SQL, you get probabilistic results. In one tab it says 240k, in another 260k. Which is right? You might be tempted to just build a table with number of users by day, so the AI takes the right number from it.
But then when the user asks the same question broken down by cohort, the answer should use the same definition of “active users” but within a very different query. You need a way to ensure that the definition of active users is deterministically reworked for the new question, not probabilistically regenerated. Once the numbers don’t add up, users lose trust.
Context Governance
Give people AI + database access and watch: they cache results, tweak queries, export CSVs that become inputs to other people’s questions. This is Excel sprawl at AI speed.
Meanwhile, important business logic lives in people’s heads. The VP of Sales knows “enterprise deal” changed meaning after the Q3 pricing overhaul. Finance knows revenue recognition rules changed with the new ERP. You need a system where that context gets captured, validated, versioned and enforced – not lost in chat threads.
Operations: Performance, Security, Observability
A sales rep asks about pipeline at 2am. They should automatically see only their region. Someone queries a three-year trend across 50M rows. It should hit pre-aggregated tables without anyone knowing those tables exist. One security leak, one unbounded query that takes down the warehouse – that’s all it takes.
And when your data changes – it always does – everything downstream must update instantly. When numbers shift, you need to trace why: which definition changed, which version was active, what’s different from last week. Without that, debugging is guesswork.
What actually works now
The teams getting this right aren’t putting AI directly on the data.
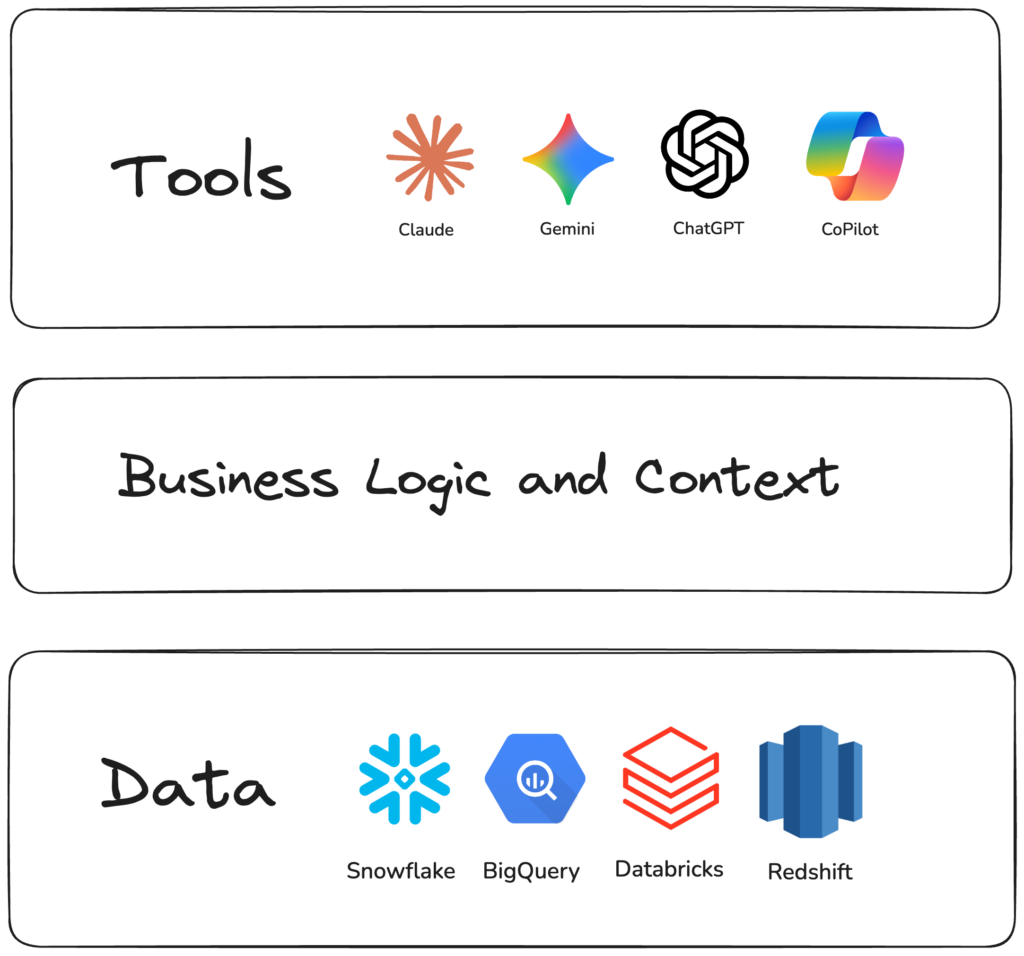
They separate the layers: Gold layer for data. Semantic layer for business logic and context. User tools go through the semantic layer to get the assurances of correctness.
They treat semantics as infrastructure: The model with the business logic and its context becomes the core data product built for end users; the semantic layer that delivers it becomes a critical component of the data stack.
They build workflows: The system only works if it can evolve. Business logic and context are versioned, tested and reviewed. Workflows are put in place for capturing new business context, reviewing changes, and deploying safely.
They plan for expansion: AI capabilities grow: co-working AIs, autonomous agents, file uploads, cross-domain questions, alerts, Slack/Teams integration. A shared foundation must support every use case – each one that bypasses it multiplies the chaos.
What’s next?
AI projects fail because they’re solving the wrong problem. The problem isn’t: “how do we make AI generate better SQL?“. The problem is: “how do we maintain governance, correctness, and trust while enabling flexible questions?“
AI changes the interface, not the architecture.
To solve architecture, look at semantic layers and what they do. Or check out Honeydew as a Semantic Layer for AI.


